Usar machine learning para predecir la satisfacción de los empleados impulsa la innovación y diseño de entornos laborales saludables. MLSEO.ai
Si bien el análisis de datos de encuestas es una herramienta fundamental en la investigación social, el marketing y la toma de decisiones empresariales, a medida que las organizaciones buscan comprender mejor a sus clientes y a su entorno, se pueden generar modelos predictivos que precisen el nivel de satisfacción de los empleados para evaluar la capacidad de respuesta organizacional.
El presente documento tiene como objetivo proporcionar un marco detallado para recopilar data, establecer objetivos, depurar datos y sentar las bases de la predicción. Se abordará el contenido desde la recolección de datos hasta la presentación de un código escrito en Python.
La metodología se regirá por un enfoque guiado para solucionar problemas comunes con procedimientos detallados.
Gobierno del Dato para la gestión de Encuestas:
los Procedimientos Detallados son la columna vertebral de cualquier investigación basada en encuestas, ya que al seguir un marco de referencia común se garantiza la calidad, la fiabilidad y la transparencia de los resultados obtenidos de cara al modelo predictivo.
Los Procedimientos Detallados para el análisis y graficación de datos de encuestas son fundamentales por varias razones:
1. Reproducibilidad y Transparencia:
- Verificabilidad: Permiten que otros investigadores puedan replicar el análisis y verificar los resultados, asegurando la validez de las conclusiones.
- Transparencia: Al detallar cada paso, se evita la manipulación de los datos y se garantiza la integridad del proceso.
2. Consistencia y Objetividad:
- Estándares: Establecen un conjunto de reglas claras que evitan la subjetividad en la interpretación de los datos.
- Consistencia: Aseguran que el análisis se realice de la misma manera en diferentes conjuntos de datos o en diferentes momentos.
3. Identificación de Errores:
- Detección temprana: Facilitan la identificación y corrección de errores en cualquier etapa del proceso, desde la recolección de datos hasta la presentación de resultados.
4. Comunicación Efectiva:
- Claridad: Permiten comunicar de manera clara y concisa los métodos utilizados y los resultados obtenidos, tanto a otros investigadores como a un público no especializado.
5. Mejora Continua:
- Aprendizaje: Sirven como base para mejorar los procesos de análisis en futuras investigaciones.
- Adaptación: Permiten adaptar los procedimientos a nuevas herramientas o metodologías.
6. Gestión de Proyectos:
- Planificación: Ayudan a planificar y organizar el proyecto de investigación, estableciendo un cronograma y asignando tareas.
- Control: Facilitan el seguimiento del progreso del proyecto y la evaluación de los resultados.
Elementos clave de un procedimiento detallado:
- Plan de análisis: Objetivos del análisis, variables a analizar, técnicas estadísticas a utilizar.
- Limpieza de datos: Identificación y corrección de errores en los datos.
- Tabulación de datos: Organización de los datos en tablas y matrices.
- Análisis estadístico: Cálculo de estadísticas descriptivas e inferenciales.
- Visualización de datos: Creación de gráficos y tablas para representar los resultados.
- Interpretación de resultados: Explicación del significado de los resultados en el contexto de la investigación.
Un enfoque de las Ciencias de Datos.
Las Ciencias de Datos componen la columna vertebral de los modelos predictivos porque parten de la Estadística para estudiar, analizar, sistematizar y correlacionar la incidencia de múltiples variables frente a un elemento en particular.
Justo aquí, es importante mencionar que la Ciencia de Datos representa el marco de referencia para construir un modelo predictivo de la satisfacción de empleados para entender mejor cómo se pueden la data para incorporarla dentro de los activos empresariales que dicten las políticas organizacionales.
A continuación se detalla un enfoque de Data Science para entender mejor cómo el Gobierno del Dato impulsa las comunicaciones organizacionales.
1. Preparación de los Datos
- Recolección de Datos
- Ejemplo: Una empresa de alimentos desea conocer la satisfacción del cliente. Diseña una encuesta con preguntas sobre la calidad del producto, el servicio al cliente y la probabilidad de recomendación.
- Limpieza de Datos
- Problema Común: Datos faltantes en las respuestas.
- Resolución: Utilizar técnicas como la imputación de datos o eliminar registros incompletos, dependiendo del porcentaje de datos faltantes.
- Problema Común: Datos faltantes en las respuestas.
2. Análisis de Datos
- Análisis Descriptivo
- Ejemplo: Después de recolectar 500 respuestas, se calcula que el 70% de los encuestados están satisfechos con el producto, con una media de satisfacción de 4.2 en una escala de 1 a 5.
- Análisis Inferencial
- Problema Común: Dificultad para determinar si los resultados son significativos.
- Resolución: Aplicar un t-test para comparar la satisfacción entre diferentes grupos (por ejemplo, edad o ubicación) y evaluar la significancia con un nivel de p < 0.05.
- Problema Común: Dificultad para determinar si los resultados son significativos.
3. Graficación de Datos
- Selección de Tipos de Gráficos
- Ejemplo: Utilizar un gráfico de barras para mostrar la distribución de respuestas sobre la calidad del producto, donde cada barra representa un rango de satisfacción (1-5).
- Diseño de Gráficos
- Problema Común: Gráficos confusos o sobrecargados.
- Resolución: Mantener un diseño limpio, usar colores contrastantes y evitar la sobrecarga de información. Incluir etiquetas claras y leyendas.
- Problema Común: Gráficos confusos o sobrecargados.
4. Interpretación de Resultados
- Contextualización
- Ejemplo: Si el análisis muestra que los clientes jóvenes están menos satisfechos que los mayores, se puede investigar más a fondo las razones detrás de esta discrepancia.
- Presentación de Resultados
- Problema Común: Dificultad para comunicar hallazgos a partes interesadas.
- Resolución: Preparar un informe que resuma los hallazgos clave, utilizando gráficos y tablas para ilustrar los puntos más importantes.
- Problema Común: Dificultad para comunicar hallazgos a partes interesadas.
Ejemplo Práctico: Cómo predecir el nivel Satisfacción de Empleados
Ahora bien, una vez adentrados en materia y entendido cómo las Ciencias de Datos impulsan la comunicación corporativa, es vital destacar que el uso de encuestras sentará las bases para saber cuál es el grado de satisfacción actual de los empleados, y posteriormente, predecir cómo serían los indicadores en el futuro.
Importante: Se debe garantizar la anonimidad de cada participante, y bajo ninún concepto se debe ventilar la identidad del entrevistado. Se recomienda usar programas que anonimicen identidades a través de formularios en línea.
- Recopilación: Recoger datos de una encuesta online enviada a todos los empleados.
- Análisis: Calcular la satisfacción promedio en diferentes dimensiones (sueldo, ambiente de trabajo, oportunidades de crecimiento), realizar tablas cruzadas para comparar grupos demográficos y realizar pruebas de hipótesis para identificar diferencias significativas.
- Graficación: Crear un gráfico de barras para comparar la satisfacción promedio en diferentes departamentos, un histograma para visualizar la distribución de los salarios y un diagrama de dispersión para analizar la relación entre años de experiencia y nivel de satisfacción.
- Interpretación: Identificar los aspectos en los que los empleados están más satisfechos y aquellos en los que se deben tomar medidas correctivas.
Modelo Predictivo de Machine Learning a partir de una Encuesta de Satisfacción de Empleados
1. Introducción El objetivo del modelo predictivo es utilizar los datos de la encuesta de satisfacción de empleados para predecir la satisfacción futura de los empleados en función de diversas características. Esto permitirá a la organización identificar áreas de mejora y anticipar problemas antes de que se conviertan en crisis.
2. Recopilación de Datos
- Datos de la Encuesta:
- Recoger respuestas de la encuesta online que incluyan variables como:
- Satisfacción general (escala de 1 a 5)
- Sueldo
- Ambiente de trabajo
- Oportunidades de crecimiento
- Años de experiencia
- Grupo demográfico (edad, género, departamento, etc.)
- Recoger respuestas de la encuesta online que incluyan variables como:
- Ejemplo de Datos: | ID Empleado | Sueldo | Ambiente de Trabajo | Oportunidades de Crecimiento | Años de Experiencia | Satisfacción | |————-|——–|———————|——————————|———————|————–| | 1 | 3000 | 4 | 3 | 5 | 4 | | 2 | 2500 | 3 | 2 | 2 | 3 | | 3 | 4000 | 5 | 4 | 10 | 5 |
3. Análisis de Datos
- Preprocesamiento:
- Limpieza de Datos: Manejar datos faltantes y eliminar duplicados.
- Codificación: Convertir variables categóricas (como departamento) en variables numéricas utilizando técnicas como One-Hot Encoding.
- Análisis Exploratorio:
-
-
- Calcular estadísticas descriptivas para cada variable.
- Realizar tablas cruzadas para comparar la satisfacción entre diferentes grupos demográficos.
-
4. Creación del Modelo Predictivo
- Selección de Algoritmos:
-
- Elegir un algoritmo de machine learning adecuado, como:
- Regresión Lineal: Para predecir la satisfacción como una variable continua.
- Árboles de Decisión: Para clasificar la satisfacción en categorías (baja, media, alta).
- Random Forest: Para mejorar la precisión del modelo.
- Elegir un algoritmo de machine learning adecuado, como:
- División de Datos:
- Dividir el conjunto de datos en un conjunto de entrenamiento (80%) y un conjunto de prueba (20%).
- Entrenamiento del Modelo:
- Utilizar el conjunto de entrenamiento para ajustar el modelo seleccionado.
- Ajustar hiperparámetros si es necesario.
- Evaluación del Modelo:
- Evaluar el modelo utilizando el conjunto de prueba.
- Utilizar métricas como el error cuadrático medio (MSE) para regresión o la precisión y la matriz de confusión para clasificación.
5. Graficación de Resultados
- Visualización de Resultados:
- Crear gráficos para mostrar la relación entre las variables predictoras y la satisfacción:
- Gráfico de barras para comparar la satisfacción promedio en diferentes departamentos.
- Histograma para visualizar la distribución de la satisfacción.
- Diagrama de dispersión para analizar la relación entre años de experiencia y nivel de satisfacción.
- Crear gráficos para mostrar la relación entre las variables predictoras y la satisfacción:
6. Interpretación de Resultados
- Identificación de Factores Clave:
- Analizar qué variables tienen mayor impacto en la satisfacción de los empleados.
- Identificar áreas donde se deben tomar medidas correctivas, como mejorar el ambiente de trabajo o aumentar las oportunidades de crecimiento.
- Predicciones Futuras:
-
- Utilizar el modelo para predecir la satisfacción de nuevos empleados o en futuras encuestas, permitiendo a la organización anticipar problemas y actuar proactivamente.
7. Conclusión El desarrollo de un modelo predictivo a partir de una encuesta de satisfacción de empleados permite a las organizaciones no solo entender el estado actual de la satisfacción laboral, sino también prever tendencias futuras. Al aplicar técnicas de machine learning, se pueden identificar factores clave que influyen en la satisfacción y tomar decisiones informadas para mejorar el ambiente laboral y la retención de empleados.
Código del Modelo Predictivo de Machine Learning para los futuros plazos de satisfacción:
Descripción del Código
- Importación de Bibliotecas: Se importan las bibliotecas necesarias para el análisis de datos, la creación del modelo y la visualización.
- Creación del DataFrame: Se crea un DataFrame de ejemplo con datos sintéticos sobre la satisfacción de los empleados.
- Separación de Características y Variable Objetivo: Se separan las características (sueldo, ambiente de trabajo, oportunidades de crecimiento, años de experiencia) de la variable objetivo (satisfacción).
- División de Datos: Se divide el conjunto de datos en un conjunto de entrenamiento y otro de prueba.
- Creación y Entrenamiento del Modelo: Se crea un modelo de regresión de Random Forest y se entrena con los datos de entrenamiento.
- Predicciones y Evaluación: Se realizan predicciones sobre el conjunto de prueba y se calcula el error cuadrático medio (MSE) para evaluar el rendimiento del modelo.
- Visualización de Resultados: Se grafican las predicciones frente a los valores reales y se muestra la importancia de las características en el modelo.
Conclusiones
Es importante notar que el conjunto de datos utilizado es pequeño y ficticio. En un entorno real, se recomienda utilizar un conjunto de datos más grande y diverso para obtener resultados más robustos y generalizables.
1. Evaluación del Modelo
- Error Cuadrático Medio (MSE): El valor del MSE impreso en la consola proporciona una medida de la precisión del modelo. Un MSE bajo indica que las predicciones del modelo están cerca de los valores reales de satisfacción. Si el MSE es relativamente bajo, esto sugiere que el modelo de Random Forest es efectivo para predecir la satisfacción de los empleados en este conjunto de datos.
2. Relación entre Satisfacción Real y Predicha
- Gráfica de Dispersión: La gráfica que muestra la satisfacción real frente a la satisfacción predicha permite visualizar la efectividad del modelo. Si los puntos están cerca de la línea de referencia (línea roja), esto indica que el modelo está haciendo buenas predicciones. Si hay una dispersión significativa, sugiere que hay factores no capturados por el modelo que podrían estar influyendo en la satisfacción de los empleados.
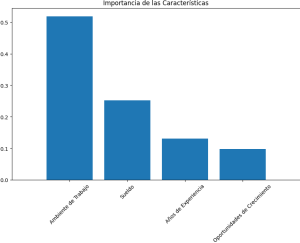
3. Importancia de las Características
- Gráfica de Importancia de Características: La gráfica que muestra la importancia de las características revela qué factores tienen mayor impacto en la satisfacción de los empleados.
- Si, por ejemplo, el “Ambiente de Trabajo” y “Oportunidades de Crecimiento” tienen una alta importancia, esto sugiere que estos son aspectos críticos que la organización debería priorizar para mejorar la satisfacción laboral.
- Un bajo nivel de importancia para “Sueldo” podría indicar que, en este conjunto de datos, otros factores son más determinantes para la satisfacción de los empleados que el salario.
Consideraciones finales:
Importancia del Uso de Machine Learning para Predecir la Satisfacción de los Empleados
El uso de machine learning para predecir la satisfacción de los empleados se ha convertido en una herramienta esencial para las organizaciones que buscan mejorar su ambiente laboral y optimizar la retención de talento. A continuación, se presentan las razones clave que destacan la importancia de esta práctica:
- Anticipación de Problemas: Al aplicar modelos predictivos, las empresas pueden identificar patrones y tendencias en la satisfacción de los empleados antes de que se conviertan en problemas significativos. Esto permite a los líderes tomar medidas proactivas para abordar las inquietudes de los empleados, evitando así la desmotivación y la rotación de personal.
- Toma de Decisiones Basada en Datos: El machine learning proporciona un enfoque basado en datos para la toma de decisiones. En lugar de depender de suposiciones o intuiciones, las organizaciones pueden utilizar análisis cuantitativos para entender mejor qué factores influyen en la satisfacción de los empleados. Esto resulta en decisiones más informadas y efectivas.
- Personalización de Estrategias: Los modelos de machine learning pueden segmentar a los empleados en diferentes grupos según sus características y niveles de satisfacción. Esto permite a las empresas personalizar sus estrategias de gestión del talento y desarrollo organizacional, adaptando las iniciativas a las necesidades específicas de cada grupo.
- Mejora Continua: La implementación de modelos predictivos no es un proceso estático. A medida que se recopilan más datos y se obtienen nuevos insights, las organizaciones pueden ajustar y mejorar continuamente sus estrategias para aumentar la satisfacción de los empleados. Esto fomenta un ciclo de mejora continua que beneficia tanto a los empleados como a la organización.
- Aumento de la Productividad y Retención: Empleados satisfechos tienden a ser más productivos y comprometidos con su trabajo. Al predecir y mejorar la satisfacción laboral, las organizaciones pueden aumentar la retención de talento, lo que a su vez reduce los costos asociados con la contratación y la formación de nuevos empleados.
- Implicaciones para la Gestión de Recursos Humanos:
- Enfoque en Áreas Clave: Las conclusiones sobre la importancia de las características pueden guiar a los líderes de recursos humanos en la formulación de estrategias para mejorar la satisfacción de los empleados. Por ejemplo, si el ambiente de trabajo es un factor clave, se podrían implementar iniciativas para mejorar la cultura organizacional o el espacio físico de trabajo.
- Personalización de Estrategias: Con la información obtenida, las organizaciones pueden personalizar sus estrategias de retención y desarrollo de talento, enfocándose en las áreas que realmente impactan la satisfacción de sus empleados.
Para finalizar, el uso de machine learning para predecir la satisfacción de los empleados no solo proporciona a las organizaciones una ventaja competitiva, sino que también contribuye a crear un entorno laboral más saludable y motivador. Al invertir en la comprensión y mejora de la satisfacción de sus empleados, las empresas pueden construir una cultura organizacional sólida que fomente el crecimiento y el éxito a largo plazo.
Por Isaías Blanco. 2024.
